
数学模型的假设、误差和迭代
一个不准确的模型
昨天,我们用最基础的指数模型预测台湾地区5月16日本土确诊病例的数量为540例。而实际公布的病例数为206例。模型预测与实际相差约2.5倍。这样的差距是由包括模型假设、误差多种因素所造成的。
模型假设
在使用指数模型时,我们做出了许多假设,包括疫情完全没有人为干预、数据准确反映社区内病例数、每日新增病例数只与时间相关。而这些假设在实际应用时与实际会有较大的出入,因而造成较大的误差。
例如,疫情完全没有人为干预的假设在现实中不成立,因为疫情响应等级在不断提升,干预措施也在不断增强。
再者,数据准确反映社区内病例数的假设也不准确。昨天我们讨论过数据的滞后性与其实际影响。而在数学建模中,数据的滞后性也会造成较大影响。突然增加的案例数量是由于增设筛检站,使滞后的数据进行更新的结果。在我们的模型中并没有可考虑到数据滞后性的调整,因此在面对突然增加案例数量(函数导数不连续增大)时,无法正确地拟合数据。
还有,每日新增病例数只与时间相关的假设简化了模型,但也未考虑很多其他的相关性。例如,与无症状感染者、境外案例、民众警觉性、防疫政策都能够直接或间接地影响新增案例数量,但由于其复杂性,无法直接纳入数学模型。
模型误差与迭代
不同模型会有不同的误差大小。我们使用的简单模型假设了许多简化假设,因此误差较大。
在疫情初期时,案例数据可能会有较大波动。 造成波动的原因包括增加的筛检站使数据从滞后回归较为即时、超级传播事件的发生、城市运作模式突然的改变等。这些变化都是模型没有纳入考虑的,造成较大的误差。
降低模型的误差有许多方法。
更新的、更多的数据能让模型与实际情况更加相符,以降低误差。
但有时我们无法获得更新或更多的数据,就像疫情模型,我们只能作回溯观察,但不可能进行对照实验。这种情况下,我们可以基于现有模型做统计运算,生成均值模型,以其降低误差。
降低误差更有效地方法使修改函数模型。 现有的模型只考虑了新增病例与前几日的相关性,且只考虑指数增加。增加一些其他有实际意义的项,如传播率、防控因子、民众响应因子等都可以降低误差。我们更可以将函数模型升级为微分方程组,达到更好的模型效果。但此类方法需要更多数学理论和数据支撑。
使用机器学习模型也可以降低误差。 机器学习模型在大量资料的基础上,能够考虑多种因素,甚至能筛选那些因素对结果的影响更大。但此类方法也需要更多数学理论和数据支撑。
模型迭代
我们在上面讨论中提到了比较简单的降低误差的方法,如均值法。这里我们将最近五日的模型预测进行平均,得到了均值预测(紫色折线):
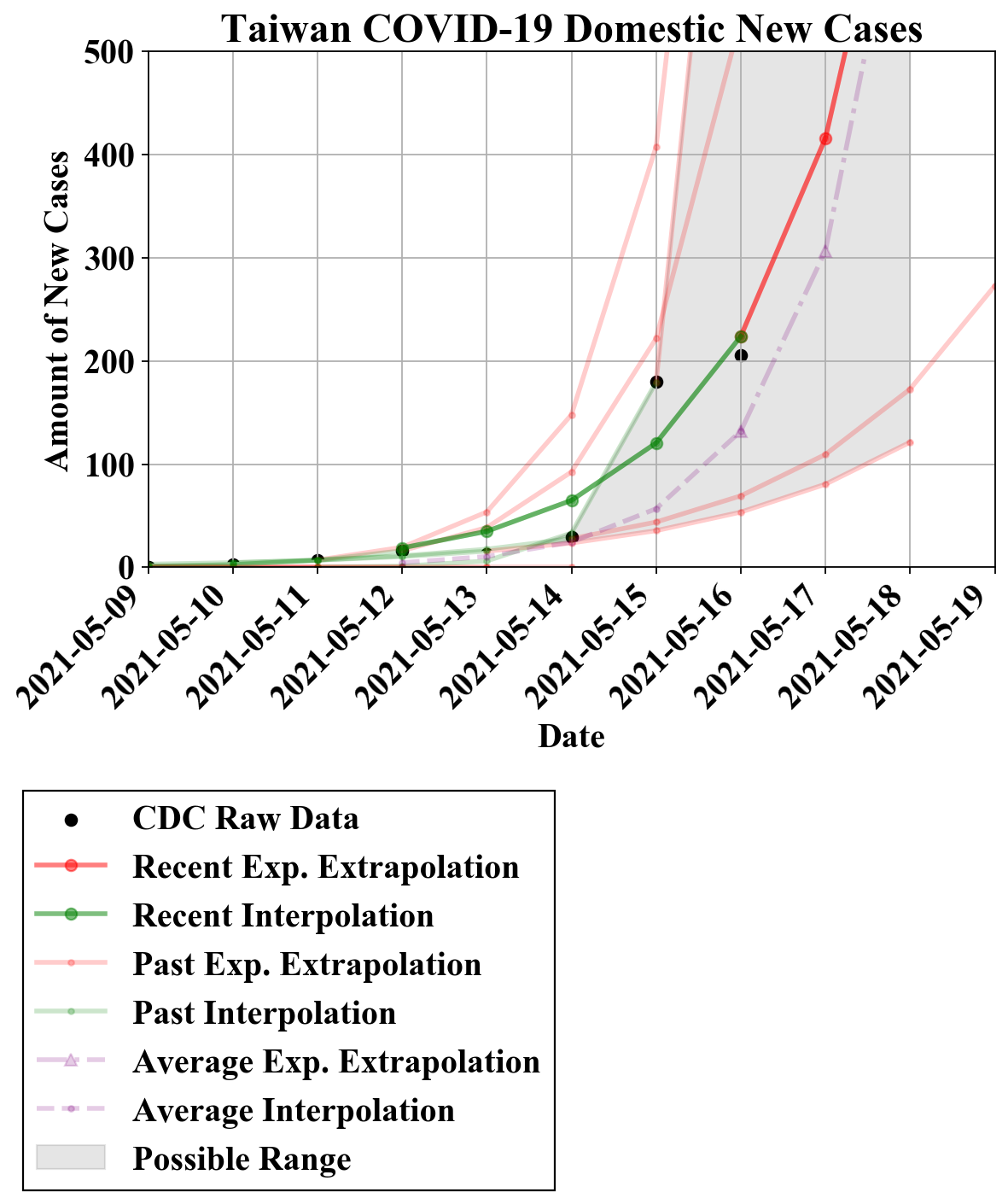
虽然模型给出了更加符合现实的约300例的预测(5月17日),但该模型仍旧有先前模型的缺陷:由于数据数值突然的增加,模型无法很好地拟合指数曲线。
我们可以从先前几日的预测中清晰地看到指数模型的上限与下限(灰色区域)。在此区域中的均值(紫色)理论上能够有更好的预测效果,但仍需要结合实际情况。
使用这些预测模型的目的并不是让模型替代人的判断,而是让模型数值对人的分析判断进行辅助。在了解其假设、限制、误差的基础上进行综合判断。
建立准确的传染病模型并非易事。事实上,全球各地的很多研究人员都投身于建立更准确的模型。例如,华盛顿大学附属的健康指标与评估研究所(Institute for Health Metrics and Evaluation, University of Washington)就根据数据和不同的假设对全球和各国疫情进行分析和预测。
UW IHME网站:https://covid19.healthdata.org/global
附录
本文也发于微信公众号。